MIT-6.824-Lab1(MapReduce)
实验要求
任务:实现分布式MapReduce
你的任务是实现一个分布式MapReduce,包括两个程序:协调者(coordinator)和工作者(worker)。系统中只有一个协调者进程,以及一个或多个并行执行的工作者进程。在真实系统中,工作者会运行在多台不同的机器上,但在本实验中,你将在单台机器上运行它们。工作者通过RPC与协调者通信。每个工作者进程将循环执行以下操作:
- 向协调者请求任务。
- 从一个或多个文件中读取任务的输入。
- 执行任务。
- 将一个或多个文件写入任务的输出。
- 再次向协调者请求新任务。
协调者应检测工作者是否在合理的时间内(本实验中使用10秒)完成任务,如果没有完成,则将相同的任务分配给其他工作者。
任务细节:实现MapReduce的Map和Reduce阶段
Map阶段
- 任务划分:Map阶段应将中间键划分为
nReduce 个桶,其中 nReduce 是Reduce任务的数量——这是 main/mrcoordinator.go 传递给 MakeCoordinator() 的参数。
- 中间文件:每个Mapper应创建
nReduce 个中间文件,供Reduce任务使用。
Reduce阶段
- 输出文件:第X个Reduce任务的输出应放在文件
mr-out-X 中。
- 输出格式:
mr-out-X 文件应包含每行Reduce函数输出。每行应使用Go的 "%v %v" 格式生成,调用时传入键和值。可以参考 main/mrsequential.go 中注释为 “this is the correct format” 的行。如果实现偏离此格式太多,测试脚本将失败。
修改文件
- 你可以修改
mr/worker.go、mr/coordinator.go 和 mr/rpc.go。
- 你可以临时修改其他文件进行测试,但确保你的代码与原始版本兼容;我们将使用原始版本进行测试。
中间文件存储
- 工作者应将中间Map输出放在当前目录的文件中,以便稍后作为Reduce任务的输入读取。
任务完成
main/mrcoordinator.go 期望 mr/coordinator.go 实现一个 Done() 方法,当MapReduce作业完全完成时返回 true;此时,mrcoordinator.go 将退出。- 当作业完全完成时,工作者进程应退出。一个简单的实现方法是使用
call() 的返回值:如果工作者无法联系协调者,它可以假设协调者已退出,因为作业已完成,因此工作者也可以终止。根据你的设计,你可能还会发现有一个“请退出”的伪任务对协调者很有帮助。
开发与调试指南
1. 开始开发
- 修改
mr/worker.go 中的 Worker() 函数,使其向协调者发送RPC请求以获取任务。
- 修改协调者,使其响应一个尚未启动的Map任务的文件名。
- 修改工作者,使其读取该文件并调用应用程序的Map函数(如
mrsequential.go 中所示)。
2. 加载Map和Reduce函数
- 应用程序的Map和Reduce函数在运行时通过Go的插件包加载,文件名以
.so 结尾。
- 如果你修改了
mr/ 目录中的任何内容,可能需要重新构建你使用的MapReduce插件,例如:1
| go build -buildmode=plugin ../mrapps/wc.go
|
3. 文件系统共享
- 本实验依赖于工作者共享文件系统。当所有工作者运行在同一台机器上时,这很简单,但如果工作者运行在不同机器上,则需要像GFS这样的全局文件系统。
4. 中间文件命名
- 中间文件的合理命名约定是
mr-X-Y,其中 X 是Map任务编号,Y 是Reduce任务编号。
5. 存储中间键值对
- 工作者的Map任务代码需要一种方式将中间键值对存储在文件中,以便在Reduce任务中正确读取。可以使用Go的
encoding/json 包:
- 写入JSON格式:
1
2
3
4
| enc := json.NewEncoder(file)
for _, kv := ... {
err := enc.Encode(&kv)
}
|
- 读取JSON格式:
1
2
3
4
5
6
7
8
| dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
kva = append(kva, kv)
}
|
6. 选择Reduce任务
- 工作者的Map部分可以使用
ihash(key) 函数(在 worker.go 中)为给定键选择Reduce任务。
7. 代码复用
- 可以从
mrsequential.go 中借鉴一些代码,用于读取Map输入文件、在Map和Reduce之间排序中间键值对,以及将Reduce输出存储在文件中。
8. 并发协调者
- 协调者作为RPC服务器是并发的;不要忘记锁定共享数据。
9. 使用Go的竞争检测器
- 使用
go run -race 运行代码。test-mr.sh 开头有注释,告诉你如何使用 -race。虽然我们在评分时不会使用竞争检测器,但如果你的代码存在竞争,即使没有竞争检测器,测试时也可能失败。
10. 工作者等待
- 工作者有时需要等待,例如Reduce任务直到最后一个Map任务完成后才能开始。一种方法是工作者定期向协调者请求任务,并在每次请求之间使用
time.Sleep() 休眠。另一种方法是协调者的相关RPC处理程序使用 time.Sleep() 或 sync.Cond 进行等待。Go为每个RPC的处理程序运行单独的线程,因此一个处理程序的等待不会阻止协调者处理其他RPC。
11. 处理工作者故障
- 协调者无法可靠地区分崩溃的工作者、因某种原因停滞的工作者以及执行过慢的工作者。最好的方法是协调者等待一段时间,然后放弃并将任务重新分配给其他工作者。在本实验中,协调者应等待10秒,之后假设工作者已崩溃。
12. 备份任务
- 如果你选择实现备份任务(第3.6节),请注意我们测试你的代码在没有工作者崩溃的情况下不会调度多余的任务。备份任务应仅在相对较长的时间(例如10秒)后调度。
13. 测试崩溃恢复
- 可以使用
mrapps/crash.go 应用程序插件测试崩溃恢复。它会在Map和Reduce函数中随机退出。
14. 确保文件完整性
- 为了确保在崩溃情况下没有人观察到部分写入的文件,MapReduce论文提到使用临时文件并在完全写入后原子重命名的技巧。可以使用
ioutil.TempFile(或Go 1.17及更高版本中的 os.CreateTemp)创建临时文件,并使用 os.Rename 原子重命名。
15. 调试输出文件
test-mr.sh 在子目录 mr-tmp 中运行所有进程,因此如果出现问题并希望查看中间或输出文件,请查看该目录。可以临时修改 test-mr.sh 以在失败测试后退出,以便脚本不会继续测试(并覆盖输出文件)。
16. 多次运行测试
test-mr-many.sh 连续多次运行 test-mr.sh,这有助于发现低概率错误。它接受一个参数,表示运行测试的次数。不要并行运行多个 test-mr.sh 实例,因为协调者会重用相同的套接字,导致冲突。
17. Go RPC注意事项
- Go RPC仅发送名称以大写字母开头的结构字段。子结构也必须具有大写的字段名称。
- 调用RPC
call() 函数时,回复结构应包含所有默认值。RPC调用应如下所示:1
2
| reply := SomeType{}
call(..., &reply)
|
reply 的任何字段。如果传递具有非默认字段的回复结构,RPC系统可能会静默返回错误值。
Lab1-实现
数据结构
根据实验指南中的提示,可以先从实现coordinator给worker分配任务开始。Worker开启后不断像coordinator申请任务,任务类型分为Map、Reduce和Done三种。
1
2
3
4
5
6
7
| type TaskType string
const (
Map TaskType = "map"
Reduce TaskType = "reduce"
Done TaskType = "done"
)
|
coordinator也在对应的三种阶段中转换,在每种对应阶段中给worker分配对应类型的任务。
1
2
3
4
5
6
7
| type Phase string
const (
MapPhase Phase = "map"
ReducePhase Phase = "reduce"
finish Phase = "finish"
)
|
所有任务被统一定义为Task结构,根据不同的TaskType区分任务类型。Status标明当前任务的执行状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| type Status string
const (
Idle Status = "idle"
Running Status = "running"
Finish Status = "finish"
)
type Task struct {
File string
Type TaskType
WorkerId string
StartTime time.Time
Status Status
TaskId int
NReduce int
}
|
此外还定义了RPC相关的请求和相应结构,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| type TaskRequest struct {
WorkerId string
Type TaskType
}
type TaskResponse struct {
Task *Task
IsDone bool
Type TaskType
}
type MapTaskDoneRequest struct {
WorkerId string
Files []string
}
type MapTaskDoneResponse struct {
}
type ReduceTaskDoneRequest struct {
WorkerId string
Files string
}
type ReduceTaskDoneResponse struct {
}
|
Coordinator实现
成员变量
1
2
3
4
5
6
7
8
9
10
| type Coordinator struct {
tasks map[TaskType][]*Task
nMap int
nReduce int
phase Phase
mu sync.Mutex
}
|
创建任务
Map Tasks
Map任务可直接在coordinator的初始化函数中创建,注意需要一个StartTime来确定是否超时。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{}
c.nMap = len(files)
c.nReduce = nReduce
c.phase = MapPhase
c.tasks = make(map[TaskType][]*Task)
for i, file := range files {
task := Task{
Type: Map,
TaskId: i,
Status: Idle,
StartTime: time.Time{},
NReduce: nReduce,
File: file,
}
c.tasks[Map] = append(c.tasks[Map], &task)
}
c.server()
return &c
}
|
Reduce Tasks
Reduce任务在所有Map任务处理完毕(状态为Finish)后创建,注意这里File字段的名字使用正则表达式,在后续处理Reduce任务时根据该表达式Retrieve对应的文件。这样可以保证不同的work处理的中间文件可以被同一个reduce任务处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| func (c *Coordinator) generateReduceTasks() {
fmt.Println("Generate reduce tasks")
for i := 0; i < c.nReduce; i++ {
task := Task{
Type: Reduce,
TaskId: i,
Status: Idle,
StartTime: time.Time{},
NReduce: c.nReduce,
File: fmt.Sprintf("%vmr-*-%v", mapfilepath, i),
}
c.tasks[Reduce] = append(c.tasks[Reduce], &task)
}
}
|
分配任务
coordinator默认在map阶段,GetTask根据当前所处阶段给worker分配不同类型的任务。注意每次分配Map任务之后都会检查所有Map任务是否全部完成,来转义coordinator的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| func (c *Coordinator) GetTask(req *TaskRequest, resp *TaskResponse) error {
c.mu.Lock()
defer c.mu.Unlock()
switch c.phase {
case MapPhase:
resp.Task = findAvailableTask(c.tasks[Map], req.WorkerId)
resp.Type = Map
if c.judgeMapDone() {
fmt.Print("Map tasks done\n")
c.phase = ReducePhase
c.generateReduceTasks()
}
case ReducePhase:
fmt.Println("Assign reduce tasks")
resp.Task = findAvailableTask(c.tasks[Reduce], req.WorkerId)
resp.Type = Reduce
if c.judgeReduceDone() {
fmt.Print("Reduce tasks done\n")
c.phase = finish
}
case finish:
task := Task{Type: Done}
resp.Task = &task
resp.IsDone = true
c.Done()
}
return nil
}
func findAvailableTask(tasks []*Task, workerID string) *Task {
for _, t := range tasks {
if t.Status == Idle || (t.Status == Running && time.Now().Sub(t.StartTime) > 10*time.Second) {
t.StartTime = time.Now()
t.Status = Running
t.WorkerId = workerID
return t
}
}
return nil
}
|
修改任务状态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| func (c *Coordinator) MapTasksDone(req *MapTaskDoneRequest, resp *MapTaskDoneResponse) error {
c.mu.Lock()
defer c.mu.Unlock()
for _, t := range c.tasks[Map] {
if t.WorkerId == req.WorkerId && t.Status == Running {
t.Status = Finish
}
}
return nil
}
func (c *Coordinator) ReduceTasksDone(req *ReduceTaskDoneRequest, resp *ReduceTaskDoneResponse) error {
c.mu.Lock()
defer c.mu.Unlock()
for _, t := range c.tasks[Reduce] {
if t.WorkerId == req.WorkerId {
t.Status = Finish
}
}
return nil
}
func (c *Coordinator) judgeMapDone() bool {
for _, t := range c.tasks[Map] {
if t.Status != Finish {
return false
}
}
return true
}
func (c *Coordinator) judgeReduceDone() bool {
for _, t := range c.tasks[Reduce] {
if t.Status != Finish {
return false
}
}
return true
}
|
Worker实现
Worker的主函数循环调用GetTasks的RPC Call。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
workerId := getWorkerId()
for {
req := TaskRequest{
WorkerId: workerId,
Type: "map",
}
resp := TaskResponse{}
ok := call("Coordinator.GetTask", &req, &resp)
if ok {
fmt.Printf("Task: %+v\n", resp.Task)
} else {
fmt.Println("No task available, wait for 1 second")
time.Sleep(1 * time.Second)
continue
}
if resp.Task != nil && resp.Type == Map {
handleMapTask(mapf, resp.Task)
}
if resp.Task != nil && resp.Task.Type == Reduce {
handleReduceTask(reducef, resp.Task)
}
if resp.Task != nil && resp.Task.Type == Done {
fmt.Println("All tasks are done")
break
}
}
}
|
处理Map任务
处理逻辑与实验说明给出的本地版本的MR类似,唯一不同的是我们要把key分类放在不同的Buckets中。实现方式是用key去做一个hash,保证相同的key在同一个bucket中即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| func handleMapTask(mapf func(string, string) []KeyValue, task *Task) {
intermediate := make([]KeyValue, 0)
file, err := os.Open(task.File)
if err != nil {
log.Fatalf("cannot open %v", task.File)
} else {
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", task.File)
}
file.Close()
kva := mapf(task.File, string(content))
intermediate = append(intermediate, kva...)
cutRes := make([][]KeyValue, task.NReduce)
for i := range cutRes {
cutRes[i] = make([]KeyValue, 0)
}
for _, kv := range intermediate {
index := ihash(kv.Key) % task.NReduce
cutRes[index] = append(cutRes[index], kv)
}
files := make([]string, 0)
for i := range cutRes {
targetName := fmt.Sprintf("mr-%v-%v", getWorkerId(), i)
targetPath := filepath.Join(mapfilepath, targetName)
targetFile, err := os.OpenFile(targetPath, os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
log.Fatalf("cannot open or create file %v: %v", targetPath, err)
}
defer targetFile.Close()
enc := json.NewEncoder(targetFile)
for _, kv := range cutRes[i] {
err := enc.Encode(&kv)
if err != nil {
log.Fatalf("cannot encode kv: %v", err)
}
}
files = append(files, targetPath)
}
mapTasksDone(files)
return
}
|
处理Reduce任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| func handleReduceTask(reducef func(string, []string) string, task *Task) {
intermediate := make([]KeyValue, 0)
files, err := filepath.Glob(task.File)
if err != nil {
log.Fatalf("cannot read %v", task.File)
}
for _, file := range files {
f, err := os.Open(file)
if err != nil {
log.Fatalf("cannot open %v", file)
} else {
}
dec := json.NewDecoder(f)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
intermediate = append(intermediate, kv)
}
}
sort.Sort(ByKey(intermediate))
res := make([]KeyValue, 0)
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := make([]string, 0)
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
res = append(res, KeyValue{intermediate[i].Key, output})
i = j
}
tempFile, err := ioutil.TempFile(reducefilepath, "mr-tmp")
if err != nil {
log.Fatalf("cannot create temp file")
}
for _, kv := range res {
fmt.Fprintf(tempFile, "%v %v\n", kv.Key, kv.Value)
}
lastChar := string(task.File[len(task.File)-1])
tmpName := fmt.Sprintf("mr-out-%v", lastChar)
err = os.Rename(tempFile.Name(), tmpName)
if err != nil {
log.Fatalf("cannot rename file")
}
fmt.Println("Reduce task done")
reduceTasksDone(reducefilepath + tmpName)
}
|
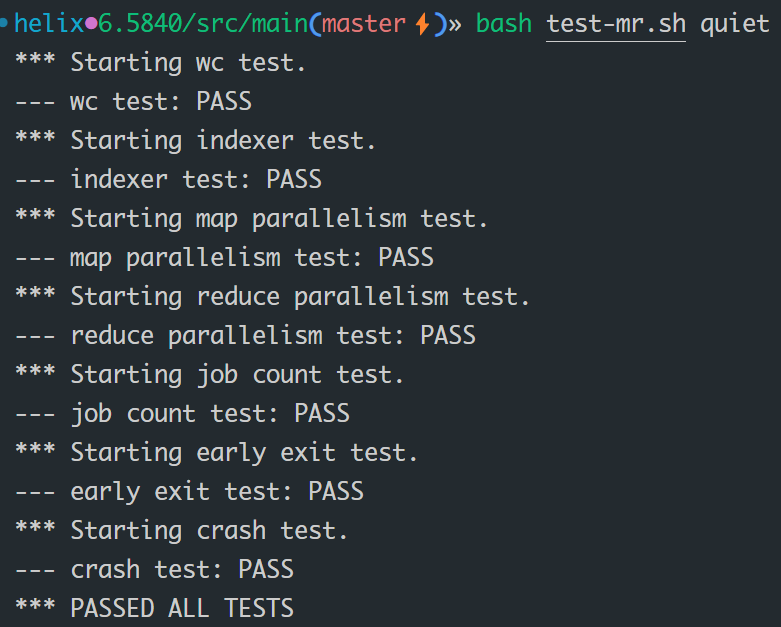
结果